Frontiers of Business Intelligence and Analytics
To understand definitions regarding the taxonomy of BI, read this paper, where an example of the methodology in the research process is used. It also discusses how the taxonomy for BI and analysis was developed, how it is applied, and an analysis of the current status with predicted development for the next wave or 3.0 of BI, as well as potential gaps. A clear diagram of the taxonomy development process is shown in Figure 6. While a picture is worth a thousand words, sometimes you must explain complex processes narratively.
Taxonomy for BI & A 3.0 research
Meta-characteristics and ending conditions
We start the process by determining the basic attributes of BI & A 3.0 suggested by Chen et al. and also applied by Eggert as the explicit meta-characteristics (step 1): sensor-based content, mobile device data, location-based analysis, person-centered analysis, context-relevant analysis, mobile visualization, and human–computer interaction. Furthermore, we determine the ending conditions as follows (step 2): The iterative taxonomy development and refinement process stops, when the taxonomy supports the goals of the structured literature review at hand. This is the case when both objective and subjective conditions of Nickerson et al. are met. In total, we determine seven objective conditions. All objects of the sample are analyzed (A). At least one object addresses each characteristic of every dimension (B). No new dimensions were added in the last iteration (C). No dimensions or characteristics changed in the last iteration (D). Each dimension is unique and not repeated (E). Every characteristic is unique within its dimensions (F). Each cell is unique and is not repeated (G). The subjective conditions comprise the attributes of a useful taxonomy: concise, robust, comprehensive, extendible, and explanatory.
For the first iteration, we decide to choose a conceptual-to-empirical approach because of the existing extensive domain knowledge of the field (step 3). As starting point, we regard the concept matrix, suggested by Eggertand apply the presented dimensions and characteristics (step 4c). The dimension Technique comprises all techniques for big data analytics according to the taxonomy of Goes. In total, seven techniques are included in this dimension: statistics, econometrics, artificial intelligence, computer-aided methods, linguistics, optimization and simulation. In contrast, the dimension Technology describes whether the research work handles data storage and data management challenges or focuses on data analysis. The characteristic Data storage handles challenges of the physical storage of mass data. Data management includes, for example, the development of data models and enables the analysis of corporate data. Finally, the characteristic Analytics consists of four sub-characteristics for the evaluation, processing and preparation of data for decision support.
Emerging research consists of five major big data research areas that are also mentioned by Chen et al.: Big data analytics comprises data mining and statistical methods on large data sets. Text analytics contains approaches that mainly focus on the analysis of text in various formats. Web analytics contains "the measurement, collection, analysis and reporting of Internet data for the purposes of understanding and optimizing Web usage". Network analytics focuses on the node relations and structure of networks and are used to understand network properties, such as centrality, betweenness, cliques or paths. Analytics of mobile data enables the analysis of "fine-grained, location-specific, context-aware, highly personalized, and content through these smart devices".
The dimension Research method and evaluation contains commonly accepted research methods in IS research, according to Oates. In total, this dimension comprises eight characteristics: Survey, Ethnography, Case studies, Experiment, Action research, and Design and conceptualization. To analyze the application scenario, for which a big data artifact is developed, the dimension Application area contains seven characteristics, which are partly derived by Chen et al.: E-government and politics, E-commerce and market research, Science, Security, Public Safety, Smart Health, Industry 4.0, and Internet of Things (IoT).
The dimension Data privacy provides a classification schema for the role of data privacy in relevant big data research articles. A user´s data privacy is defined as "how, and to what extent information about them is communicated to others". This criterion is of particular importance since manifold data privacy regulations, such as the EU General Data Protection Regulation, have been enacted. IS research already addresses this topic using data anonymization. The dimension distinguishes between the absence of data privacy implications (Not addressed), the explicit mentioning of data privacy risks and problems (Risks & problems mentioned) as well as the proposal of a concrete solution (Introduction of a solution).
In step 5c, we examine a sample of ten literature objects out of our final result set to review the dimensions and characteristics. We provide the classification results of the first iteration in Appendix A. Based on the results, we create the initial concept matrix (Step 6c), which is comparable to the one suggested by Eggert (Fig. 7). Finally, we check whether the ending conditions are met (Step 7). Five quantitative conditions (B), (C), (D), (E) and (F) as well as the qualitative conditions are not met. For taxonomy improvement, we begin a second iteration.
Fig. 7

Taxonomy draft after first iteration
For the second iteration, we decide to use the conceptual-to-empirical approach again as the taxonomy resulted from iteration one can be further conceptually improved (step 3). In iteration one, we allow one object to address multiple characteristics within one dimension to receive a comprehensive taxonomy. In turn, this leads to a complex taxonomy, making it difficult to review one single object. Therefore, we conceptualize a refined taxonomy, in which each object from the sample set addresses exactly one characteristic in one dimension (Step 4c).
We delete the dimension BI & A 3.0 attributes as it is represented by the meta-characteristics of the taxonomy. Furthermore, we replace the sub dimension analytics by the dimension Analytics maturity to prevent sub-dimensions in the taxonomy. Analytics maturity contains the evolution of data analytics approaches and is based on the widely accepted Gartner Business Analytics Framework. The framework distinguishes between Descriptive (what happened?), Diagnostic (why did it happen?), Predictive (what will happen?) and Prescriptive (how can we make it happen?) approaches.
To increase the explanatory value of the taxonomy, we review the remaining characteristics and dimensions and deleted those which are of low explanatory value like Computer-supported methods (dimension Techniques) and Science (dimension Application area). We added the characteristics Data science foundation and human computer interaction (HCI) in the dimension Emerging research area. The characteristics IoT and Industry 4.0 within the dimension Application area are not fully distinct and therefore merged. The characteristic E-commerce and market research (dimension Application area) is renamed into Market intelligence to have a more precise expression. By analyzing the hits for techniques and technologies, we found out that they are not distinct. Thus, we merge the remaining characteristics of the dimensions Techniques and Technologies into one dimension.
Again, we apply the revised taxonomy to the same sample set of literature objects to evaluate the dimensions and characteristics (step 5c). All classification results of the second iteration are provided in Appendix B. Afterwards, we create the second taxonomy draft, which we provide in Fig. 8 (step 6c). In step 7 of iteration two, we check whether the ending conditions are met. Even the revised taxonomy does not meet the quantitative conditions. From a quantitative perspective, objectives A, B, C, D, E and F are still not fulfilled. Three literature objects are left that could not be fully classified, which is in conflict with condition B.
Fig. 8

Taxonomy draft after second iteration
The results of iteration two still have the potential to be conceptually improved since we could not classify all objects. Thus, for the third iteration, we decide to use the conceptual-to-empirical approach again (step 3). Once again, we adjust the taxonomy draft (step 4c). We split the dimension Techniques and technologies into two separate dimensions Technologies and Analysis techniques, as we want to map the characteristics of each dimension more precisely. The newly created dimension Technologies consists of the characteristics Analytics, Data Storage, Data Management, and Visualization. We apply this dimension to give a general overview of the fundamental BI & A technologies. The second new dimension Analysis techniques consists of the characteristics Econometrics, Linguistics, Optimization, Statistics, and Non analytics.
Furthermore, we change the dimension Research method and evaluation entirely because in iteration two we cannot use this dimension for classifying the literature objects from the sample set. Three out of ten papers cannot be classified with the taxonomy of iteration two. We reviewed the literature for other potential approaches to map common IS research methods. We identified the work of Wilde and Hess and the follow-up research by Schreiner et al., which offer a comprehensive taxonomy containing a finer granularity compared to the taxonomy drafts in iterations 1 and 2. The new derived characteristics are: Deductive analysis (formal, conceptual, argumentative), Simulation, Reference modeling, Action research, Prototyping, Ethnography, Case study, Grounded theory, Cross-sectional study and Lab or field experiment. We find research works that apply more than one research method like Musto et al. To address this kind of mixed methods research work, we decide to allow the classification of a primary and secondary research method, indicated by a p and s.
In step 5c, we again examine the same sample set of ten literature objects and review the revised dimensions and characteristics. We provide all classification results in Appendix C. Afterwards we create the third taxonomy draft (step 6c), which is depicted in Fig. 9. Finally, we check the ending conditions (step 7). Condition A and B are fully supported. Since we changed dimensions and characteristics, the conditions C and D are not met. Each dimension is now unique, so that the current taxonomy draft fulfills condition E. All characteristics in the dimensions are unique, which fulfills ending condition F. In addition, the subjective conditions are met for this small sample, so that we perceive this taxonomy draft as mature enough to conduct an empirical evaluation.
Fig. 9
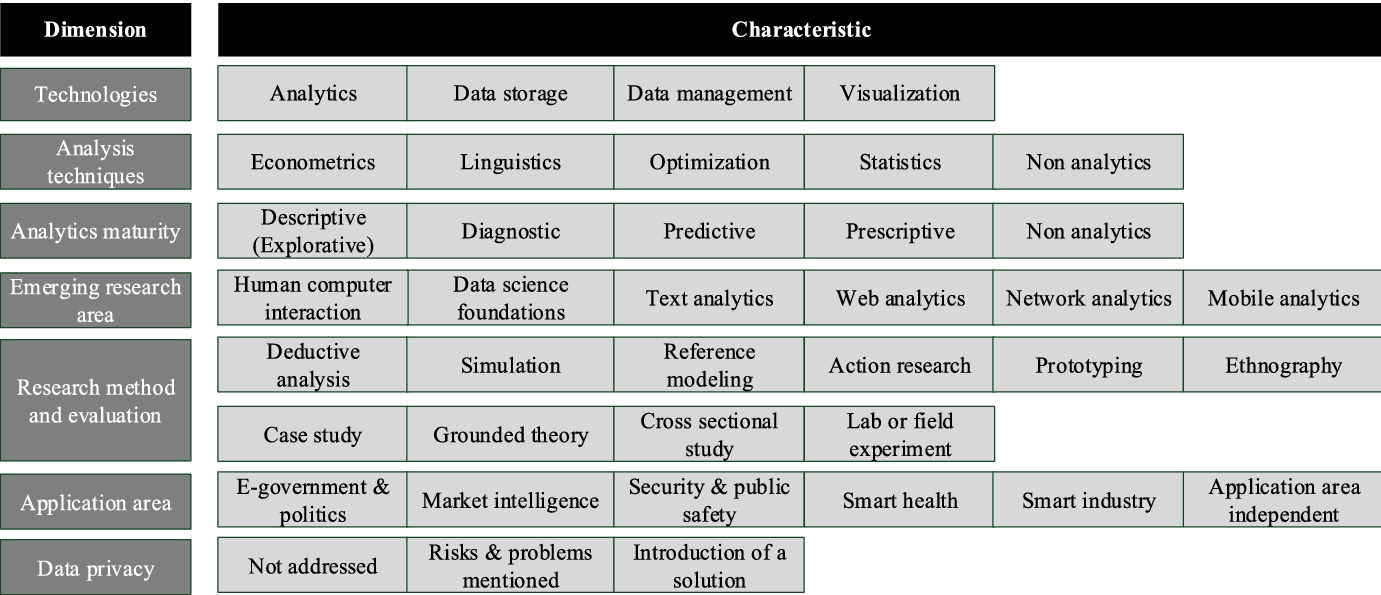
Taxonomy draft after third iteration